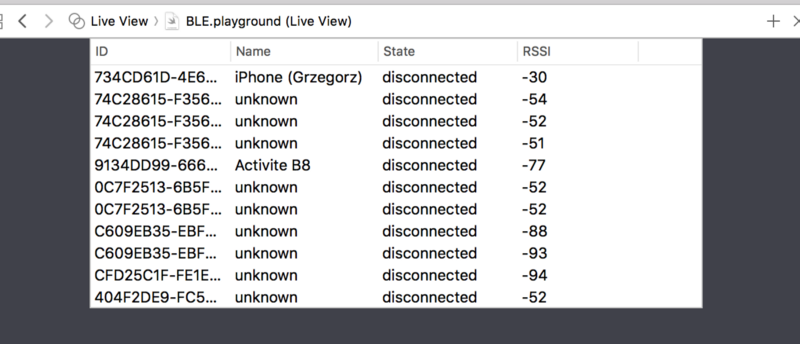
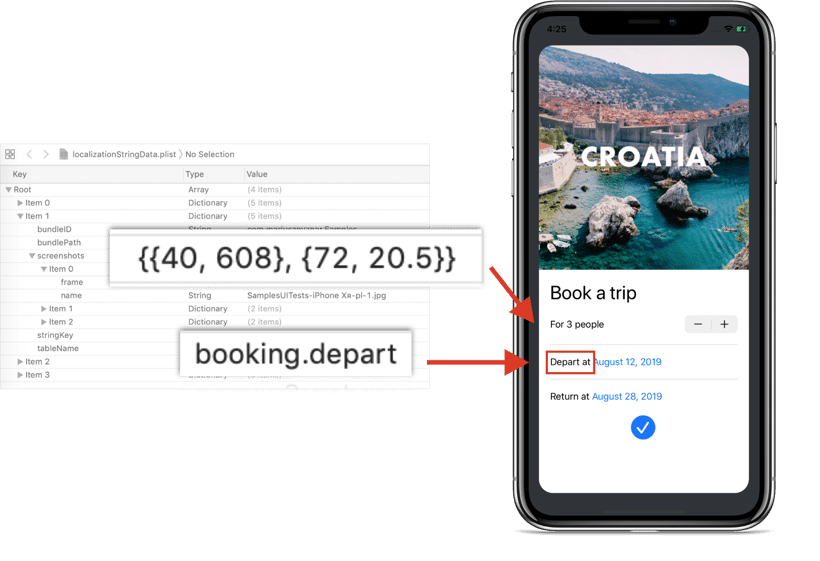
Writingforinnovationkingd
Blog posts that (hopefully) will make you think. About MedTech innovations and tech solutions that turn to tools of social sustainability.
Blog posts that (hopefully) will make you think. About MedTech innovations and tech solutions that turn to tools of social sustainability.
results (27)
result for:
reset